Les cyberattaques visant les petites et moyennes entreprises (PME) au Canada ont grimpé en coût et en fréquence. Un seul outil — comme un antivirus ou un pare-feu — ne suffit plus. La voie la plus sûre consiste à adopter une stratégie de cybersécurité multicouche qui superpose sept couches pratiques : humaine, périmètre, réseau, application, terminal, données et actifs. Ensemble, elles réduisent la probabilité d’une atteinte, limitent le rayon d’impact lorsque des incidents surviennent et accélèrent le rétablissement afin que votre entreprise puisse continuer d’opérer.
Ce guide explique chaque couche en termes d’affaires : pourquoi elle est importante, les principaux risques, à quoi ressemble une bonne pratique et les mesures à prendre avec responsables et échéanciers. Vous verrez aussi comment ces couches s’alignent sur le Zero Trust (confiance zéro : ne jamais faire confiance, toujours vérifier) et sur des cadres reconnus comme MITRE ATT&CK et la Cyber Kill Chain. L’objectif : une feuille de route pragmatique que vous pouvez amorcer dès ce trimestre — sans effectifs ni budget « grande entreprise ».
Pourquoi la sécurité multicouche est essentielle pour les PME
Les attaquants misent rarement sur un seul stratagème. Une atteinte typique enchaîne plusieurs faiblesses : par exemple, un courriel d’hameçonnage qui vole un mot de passe, lequel ouvre un accès à distance, qui permet ensuite un mouvement latéral sur un réseau non segmenté, et qui se termine par un vol de données ou un rançongiciel. Lorsque vous renforcez plusieurs couches, vous brisez cette chaîne à plusieurs endroits et forcez les adversaires à travailler beaucoup plus fort, souvent assez bruyamment pour que vos outils de surveillance les repèrent à temps.
Les clients, partenaires et assureurs demandent de plus en plus une preuve de contrôles de base. De nombreux questionnaires de cyberassurance exigent désormais l’authentification multifacteur (AMF), des sauvegardes immuables, la surveillance des terminaux et un plan d’intervention en cas d’incident.
Une approche multicouche facilite les audits et les renouvellements, puisque la preuve fait partie intégrante de vos opérations. Surtout, lorsque des incidents se produisent — et cela arrivera — des couches comme la segmentation, l’EDR/MDR (détection et réponse aux terminaux / service géré) et des sauvegardes testées vous évitent de longues périodes d’arrêt qui autrement freineraient les ventes et mineraient la confiance.
FAQ:
Un bon antivirus, est-ce suffisant?
L’antivirus intercepte des fichiers malveillants connus, mais les attaquants modernes se connectent souvent avec des identifiants volés, abusent d’outils natifs et opèrent dans des applications infonuagiques où les outils traditionnels ont peu de visibilité. Des couches comme l’AMF, l’EDR/MDR, la segmentation réseau et des sauvegardes testées comblent ces lacunes et limitent les dommages lorsque la prévention échoue.
Nous sommes petits — sommes-nous vraiment une cible?
La taille ne vous protège pas. Des balayages automatisés ratissent l’internet à la recherche de services exposés et de mots de passe faibles, et les attaques de chaîne d’approvisionnement visent des partenaires de toutes tailles. Les PME canadiennes détiennent des identifiants et des données de valeur et sont souvent connectées à de plus grandes entreprises, ce qui en fait des tremplins attrayants.
Par où commencer si le budget est serré?
Concentrez-vous sur quatre contrôles offrant le meilleur rapport réduction du risque / dollar : activez l’AMF partout où c’est possible, déployez un EDR avec surveillance 24 h/24, 7 j/7, vérifiez que vos sauvegardes sont immuables et restaurables, et offrez une formation pratique à l’hameçonnage avec un mécanisme simple de signalement. Ces mesures perturbent la majorité des attaques réelles que nous observons.
Comment mesurer les progrès?
Choisissez quelques indicateurs et rapportez-les chaque mois : taux de clic aux hameçonnages, couverture de l’AMF, couverture de l’EDR, conformité des correctifs pour les mises à jour critiques, délai moyen d’isolement d’un hôte et statut des tests de restauration des sauvegardes. Lorsque ces tendances s’améliorent, votre risque diminue.
Avons-nous besoin du Zero Trust?
Le Zero Trust est surtout un état d’esprit, pas un produit. Vérifiez l’identité et l’état de santé des appareils à chaque accès, n’accordez que les privilèges nécessaires à la tâche et segmentez par défaut. Vous pouvez l’implanter progressivement en vous appuyant sur les sept couches décrites ici.
Et la cyberassurance?
La plupart des assureurs exigent maintenant une preuve d’AMF, de surveillance des terminaux, de sauvegardes immuables et d’un plan d’intervention documenté. Ce guide se mappe directement à ces attentes et vous aide à préparer les questionnaires et renouvellements.
À quelle fréquence tester l’intervention en cas d’incident?
Une simulation sur table d’une heure chaque trimestre suffit pour mettre au jour les lacunes de communication, les étapes techniques et la prise de décision. Impliquez les TI, la finance, les communications et la direction, et faites tourner des scénarios comme la fraude par virement bancaire, le rançongiciel et la fuite de données.
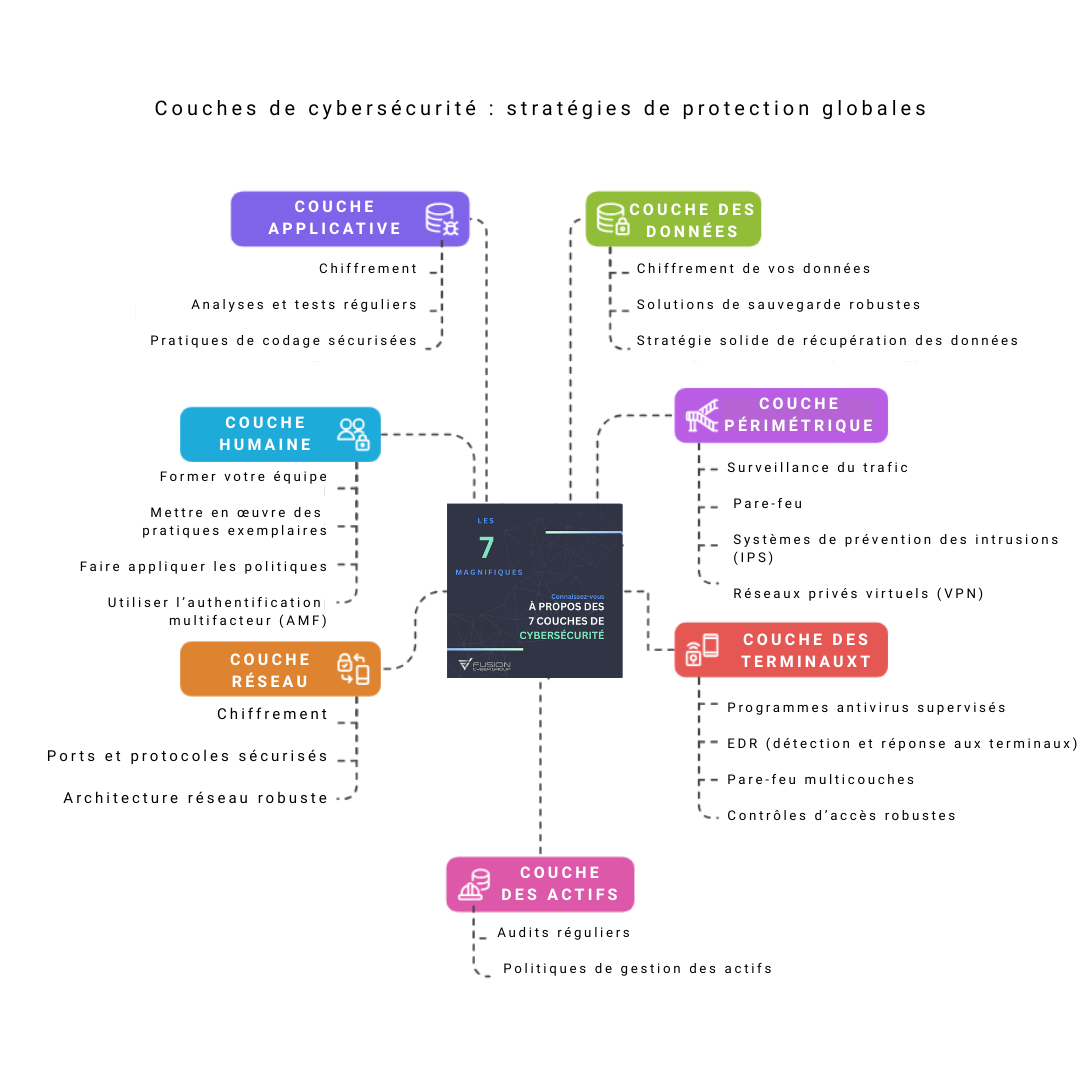

1) Couche humaine — transformer les personnes en pare-feu humain
Définition. La couche humaine regroupe toutes les personnes pouvant influencer votre posture de sécurité : employés, dirigeants, sous-traitants et même fournisseurs clés ayant un accès. C’est la porte d’entrée de l’ingénierie sociale — hameçonnage par courriel, smishing par messages texte (SMS), bombardement de demandes d’AMF (MFA fatigue) et, de plus en plus, hypertrucages (deepfakes) audio ou vidéo convaincants utilisés pour faire pression sur les équipes financières et les dirigeants.
Pourquoi c’est important. La majorité des attaques réussies commencent par une interaction humaine, pas par une faille purement technique. Lorsque les personnes reconnaissent rapidement une activité suspecte et la signalent, votre équipe peut enquêter avant que des identifiants ne soient détournés ou que des virements bancaires ne soient redirigés. De bonnes habitudes — utiliser un gestionnaire de mots de passe, activer l’AMF et vérifier les demandes par un second canal — réduisent la probabilité qu’une seule erreur provoque un arrêt d’affaires.
Risques courants dans les PME. On observe fréquemment la réutilisation de mots de passe entre comptes personnels et professionnels, l’absence d’AMF sur le courriel et l’accès à distance, ainsi qu’une culture d’« exception pour les dirigeants » où certaines mesures sont épargnées pour des raisons de commodité.
Les équipes des finances et des RH sont des cibles récurrentes d’arnaques aux cartes-cadeaux et de modifications frauduleuses des coordonnées de paiement, et de nombreuses organisations n’ont pas de mécanisme simple et bien connu pour signaler des messages suspects, de sorte que des incidents potentiels ne sont pas rapportés avant qu’il ne soit trop tard.
À quoi ressemble une bonne pratique. Une couche humaine efficace combine des formations de sensibilisation fréquentes et courtes avec des simulations d’hameçonnage réalistes qui visent l’apprentissage plutôt que la culpabilisation. L’AMF est imposée partout où c’est possible — courriel, VPN ou accès réseau Zero Trust (ZTNA), Microsoft 365 ou Google Workspace, systèmes financiers et administration à distance.
Les politiques sont rédigées en langage clair et restent concises, couvrant l’utilisation acceptable, le télétravail, l’APPA (apportez votre propre appareil — BYOD) et le signalement des incidents. Des rappels utiles sont intégrés au flux de travail, comme des bandeaux « Expéditeur externe » et des incitations dans l’application du gestionnaire de mots de passe, de sorte que la sécurité devienne la valeur par défaut plutôt qu’une réflexion après coup.
Mesures, responsables et échéancier. Au cours des 30 premiers jours, demandez aux RH et aux TI de déployer conjointement un gestionnaire de mots de passe, d’activer l’AMF pour le courriel et l’accès à distance, et d’ajouter un bouton bien visible « Signaler un hameçonnage » dans le client de messagerie. Entre 30 et 60 jours, lancez des formations trimestrielles courtes et des simulations d’hameçonnage mensuelles, puis formalisez une politique disciplinaire équitable et claire.
D’ici 60 à 90 jours, prévoyez un exposé exécutif sur les hypertrucages et la fraude aux paiements et réalisez un exercice sur table guidant les finances, le service juridique et les TI à travers un scénario de fraude par virement, de la détection au rétablissement.
Indicateurs qui comptent. Suivez votre taux de clic sur les courriels d’hameçonnage et visez à le maintenir sous les cinq pour cent au fil du temps, mesurez la couverture de l’AMF et poussez-la vers une adoption quasi universelle, puis surveillez le délai moyen entre la réception d’un courriel suspect et son signalement — quinze minutes ou moins constitue un solide indicateur que la couche humaine fonctionne.

2) Couche périmétrique — les murs et les ponts-levis
Définition. La couche périmétrique englobe les contrôles qui séparent votre environnement interne de l’internet public et des réseaux de partenaires. Elle comprend les pare-feu, la prévention des intrusions, l’accès à distance sécurisé et les services de protection placés en amont des applications accessibles au public.
Pourquoi c’est important. La plupart des attaques automatisées commencent par des balayages de l’internet à la recherche de services exposés, de mots de passe faibles et de systèmes non corrigés. Un périmètre bien configuré bloque le trafic reconnu comme malveillant, impose une authentification forte aux utilisateurs à distance et canalise tous les accès par des points de passage surveillés où il est plus facile de détecter et d’arrêter les abus. Le périmètre n’arrêtera pas toutes les menaces modernes, mais il élimine les cibles faciles et donne du temps à vos défenseurs.
Risques courants dans les PME. Le protocole d’accès à distance RDP (Remote Desktop Protocol) exposé reste un problème récurrent, car il est pratique et souvent laissé sans protection. Les anciens pare-feu sont fréquemment configurés avec des règles « allow any » trop larges qui avaient du sens lors d’une migration mais n’ont jamais été resserrées. Les VPN hérités, sans AMF (authentification multifacteur) ni vérification de la posture des appareils, permettent à des identifiants compromis d’entrer directement dans le réseau. Les interfaces d’administration des routeurs, pare-feu et applications web sont parfois laissées accessibles depuis l’internet pour un soutien « rapide ».
À quoi ressemble une bonne pratique. Un périmètre moderne s’appuie sur des pare-feu de nouvelle génération (NGFW) avec prévention des intrusions (IPS), filtrage sensible aux applications et blocage géo-IP pour les régions que vous ne desservez pas. L’accès à distance est assuré par un accès réseau Zero Trust (ZTNA) ou par un VPN durci qui exige toujours l’AMF et vérifie l’état de santé de l’appareil avant d’accorder l’entrée.
Les applications exposées sur le web sont placées derrière un pare-feu applicatif web (WAF), et tous les journaux du périmètre sont acheminés vers une plateforme centrale SIEM ou XDR afin que votre centre des opérations de sécurité (SOC) repère rapidement les schémas suspects. Les changements de règles suivent un processus simple et documenté, revu chaque trimestre.
Mesures, responsables et échéancier. Confiez à votre responsable réseau ou à votre MSP, sous l’égide de la direction des opérations, la fermeture du RDP public et la restriction de toutes les interfaces d’administration à des adresses internes dans les 30 premiers jours. En parallèle, imposez l’AMF sur votre VPN et activez les signatures IPS du pare-feu.
Au cours des 30 à 60 jours suivants, déployez un ZTNA ou durcissez le VPN existant avec des vérifications de posture des appareils, créez des profils d’accès distincts pour les partenaires et envoyez tous les événements du périmètre à votre SIEM. D’ici 60 à 90 jours, ajoutez le blocage géo-IP pour les régions non desservies, ajustez les règles selon le principe du moindre privilège et placez les applications publiques derrière un WAF avec des protections de base contre les robots et les attaques DDoS activées.
Indicateurs qui comptent. Dénombrez vos services exposés au public et assurez-vous que la liste correspond à la réalité; les expositions inattendues devraient tendre vers zéro. Vérifiez que 100 % des sessions à distance utilisent l’AMF et un appareil conforme. Suivez le délai entre le premier contact d’une adresse IP malveillante avec votre périmètre et son blocage; les programmes de pointe le mesurent en secondes grâce aux flux de menaces automatisés et aux politiques.

3) Couche réseau — visibilité et segmentation à l’intérieur des murs
Définition. La couche réseau couvre les voies de circulation à l’intérieur de votre environnement — commutateurs, routeurs et réseaux sans fil — qui transportent les données entre serveurs, terminaux et passerelles vers le nuage. C’est là que la segmentation et la surveillance interne permettent soit de contenir une brèche, soit de la laisser se propager.
Pourquoi c’est important. Une fois qu’un attaquant a mis un pied dans la porte, la facilité avec laquelle il peut se déplacer latéralement détermine l’ampleur des dégâts. Une segmentation réseau adéquate rend difficile le passage d’un portable compromis à un serveur financier ou d’un Wi-Fi invité à vos systèmes métier. Le chiffrement des protocoles d’administration et l’observation du trafic est-ouest vous aident à détecter des mouvements anormaux avant qu’un rançongiciel ne puisse se déployer à grande échelle.
Risques courants dans les PME. Beaucoup de PME fonctionnent sur un réseau plat où tout se trouve sur le même VLAN, ce qui rend trivial le déplacement de logiciels malveillants entre services. Les mots de passe Wi-Fi partagés se multiplient avec le temps et changent rarement, plaçant des appareils inconnus sur les réseaux de production. Des protocoles hérités comme SMBv1 et Telnet demeurent activés parce qu’« ils fonctionnent encore », offrant des cibles faciles aux acteurs qui affectionnent les techniques anciennes mais éprouvées.
À quoi ressemble une bonne pratique. Un réseau bien conçu sépare le trafic selon la fonction d’affaires et la sensibilité — finances, serveurs, terminaux, OT/IoT (TO/IdO) et invités — puis bloque par défaut les accès inter-VLAN, en n’autorisant que les ports et protocoles précisément requis par les flux de travail.
L’administration utilise exclusivement des protocoles chiffrés tels que SSH et TLS 1.2+, et un contrôle d’accès au réseau (NAC) léger ou une vérification de posture Wi-Fi s’assure que seuls des appareils conformes se connectent. La détection d’intrusion interne et l’analytique comportementale surveillent le trafic est-ouest à la recherche de connexions inhabituelles, que votre centre des opérations de sécurité (SOC) triera en priorité.
Mesures, responsables et échéancier. Au cours du premier mois, isolez le Wi-Fi invité sur son propre réseau, désactivez les protocoles hérités et faites la rotation des phrases secrètes Wi-Fi partagées. Entre les jours 30 et 60, créez des VLAN pour les serveurs, les finances et les terminaux, puis appliquez entre eux des règles de moindre privilège afin que seul le trafic requis soit permis.
De 60 à 90 jours, ajoutez du NAC ou des contrôles basés sur l’adresse MAC pour restreindre davantage l’accès, déployez des sondes IDS/IPS internes et envoyez ces journaux à votre SIEM tout en établissant la ligne de base du trafic interne normal.
Indicateurs qui comptent. Suivez le nombre de segments distincts et comparez-le à vos fonctions d’affaires; la plupart des PME devraient en compter au moins quatre. Mesurez la proportion du trafic administratif interne qui est chiffré et progressez vers une couverture complète. Enfin, surveillez et enquêtez sur toutes les tentatives de mouvement latéral bloquées chaque mois, avec l’objectif de les repérer plus tôt et de les corriger plus rapidement au fil du temps.

4) Couche applicative — sécuriser les logiciels que vous utilisez et développez
Définition. La couche applicative englobe les applications infonuagiques (SaaS), les systèmes métier locaux (on-premise) et tout logiciel ou site web personnalisé que vous maintenez. Dans les environnements modernes, elle inclut aussi les API et les intégrations qui déplacent discrètement des données entre les systèmes.
Pourquoi c’est important. Les attaquants visent de plus en plus la couche applicative par la prise de contrôle de comptes, les erreurs de configuration et les faiblesses de la chaîne d’approvisionnement logicielle. Des rôles surdimensionnés en permissions, des comptes utilisateurs dormants et des API non sécurisées ouvrent des voies silencieuses vers des données sensibles. Si votre entreprise développe du logiciel, des dépendances vulnérables et une mauvaise hygiène des secrets peuvent introduire des risques bien avant que le code n’atteigne la production.
Risques courants dans les PME. On constate souvent que l’AMF (authentification multifacteur) est activée dans certaines applications mais pas dans d’autres, et que l’authentification unique (SSO) n’a pas été étendue aux outils de finances, de RH ou de CRM. Les rôles SaaS commencent fréquemment très larges « pour que ça marche » et ne sont jamais resserrés.
Le TI fantôme apparaît quand des équipes adoptent des outils sans la visibilité des TI, et des clés d’API ou des identifiants se retrouvent parfois dans des dépôts de code ou des documents partagés. Pour les applications web auto-hébergées, des problèmes connus comme l’injection SQL et les scripts intersites (XSS) persistent sans tests réguliers.
À quoi ressemble une bonne pratique. Une sécurité applicative mature place le SSO et l’AMF devant chaque plateforme SaaS critique et réalise des revues d’accès trimestrielles pour ajuster les privilèges au juste nécessaire. Des politiques de prévention des pertes de données (DLP) sont activées dans le courriel et le stockage en nuage afin d’éviter les fuites accidentelles.
Si vous développez ou personnalisez du logiciel, un cycle de développement sécurisé (SDLC) inclut des tests statiques et dynamiques, l’analyse des dépendances et des conteneurs, ainsi qu’un processus explicite pour garder les secrets hors du code. Un outil de gestion de la posture de sécurité des SaaS (SSPM) aide à déceler les mauvaises configurations dans les applications infonuagiques avant les adversaires.
Mesures, responsables et échéancier. Dans les 30 premiers jours, activez l’AMF et le SSO pour Microsoft 365 ou Google Workspace ainsi que pour tout système financier ou CRM, puis supprimez au passage les comptes inutilisés. Au cours des 30 à 60 jours suivants, formalisez des revues d’accès trimestrielles, activez les politiques DLP pour le courriel et les espaces de fichiers infonuagiques, et analysez vos dépôts afin d’y détecter des identifiants exposés, en rotant tout secret trouvé.
D’ici 60 à 90 jours, ajoutez le SAST/DAST à votre pipeline CI/CD si vous développez du code, adoptez un SSPM pour surveiller la posture de vos SaaS et publiez une norme de codage sécurisé concise que vos équipes peuvent réellement suivre.
Indicateurs qui comptent. Visez cent pour cent des applications critiques protégées par SSO et AMF, et mesurez la réduction des permissions excessives après chaque cycle de revue. Suivez le délai de correction des constats applicatifs de gravité élevée et maintenez-le sous trente jours, avec des fenêtres d’urgence pour les enjeux critiques nécessitant une attention immédiate.

5) Couche des terminaux — portables, postes de travail, mobiles et serveurs
Définition. La couche des terminaux englobe chaque appareil en contact avec votre entreprise — des ordinateurs portables et téléphones intelligents des employés jusqu’aux serveurs locaux et machines virtuelles (VM) infonuagiques. C’est la surface où les attaquants atterrissent le plus souvent en premier et l’endroit où la détection et le confinement rapides rapportent le plus.
Pourquoi c’est important. La plupart des infections par logiciels malveillants et des intrusions avec présence humaine (hands-on-keyboard) commencent sur un terminal. Des contrôles solides à ce niveau, combinés à une surveillance 24 h/24, 7 j/7, réduisent considérablement le temps dont dispose un adversaire pour hausser ses privilèges, se déplacer latéralement ou déployer un rançongiciel. L’application régulière des correctifs et le durcissement des configurations ferment les brèches exploitables, et le chiffrement complet du disque empêche qu’un portable perdu ne se transforme en atteinte à la protection des données.
Risques courants dans les PME. Les appareils prennent souvent du retard sur les correctifs du système d’exploitation et des applications tierces parce que les mises à jour perturbent le travail. De nombreux utilisateurs conservent des droits d’administrateur local par commodité, ce qui transforme un simple hameçonnage en compromission totale.
L’antivirus traditionnel fonctionne en arrière-plan sans supervision active, de sorte que des détections peuvent passer inaperçues pendant des jours. Les téléphones personnels (APPA — apportez votre propre appareil, BYOD) se connectent fréquemment aux ressources de l’entreprise sans contrôle, et certains portables demeurent non chiffrés en raison de pratiques héritées.
À quoi ressemble une bonne pratique. Une protection moderne des terminaux commence par l’EDR (Endpoint Detection and Response — détection et réponse aux terminaux), capable de repérer les comportements suspects, idéalement appuyée par un MDR (Managed Detection and Response — service géré) qui surveille en continu. La gestion des correctifs est centralisée et mesurée, avec des mises à jour critiques appliquées en moins de deux semaines.
Le chiffrement de disque est activé par défaut et les clés sont mises en séquestre de façon sécurisée. Une plateforme de gestion des appareils mobiles (MDM) impose une hygiène de base, comme le verrouillage d’écran et l’effacement à distance des téléphones intelligents. Le principe du moindre privilège est la norme : les utilisateurs se connectent avec des comptes standards et les administrateurs utilisent des identifiants distincts et protégés uniquement au besoin.
Mesures, responsables et échéancier. Dans les 30 premiers jours, déployez l’EDR sur tous les appareils pris en charge, activez le chiffrement intégral du disque sur l’ensemble du parc et retirez les droits d’administrateur local des comptes utilisateur courants.
Entre les jours 30 et 60, mettez en place une gestion centralisée des correctifs pour les systèmes d’exploitation et les applications usuelles, inscrivez les appareils mobiles dans le MDM avec des politiques pragmatiques et appliquez un profil de durcissement de base aligné sur le CIS ou des lignes directrices comparables. Au cours des 30 jours suivants, ajoutez une liste d’autorisation des applications (allow-listing) pour les rôles à risque élevé ou à privilèges élevés et automatisez des procédures d’isolement afin que votre SOC puisse mettre en quarantaine un appareil compromis d’un seul clic.
Indicateurs qui comptent. Surveillez la couverture de l’EDR et maintenez-la au-delà de 98 %, mesurez la conformité des correctifs pour les vulnérabilités critiques et gardez-la au-dessus de 95 % dans un délai de quatorze jours, puis testez le temps nécessaire pour isoler un terminal compromis — cinq minutes ou moins constitue une cible réaliste et précieuse.

6) Couche des données — protéger l’information elle-même
Définition. La couche des données se concentre sur les renseignements sensibles où qu’ils se trouvent : dans des fichiers et bases de données au repos, dans des sauvegardes, et en transit par courriel, API et outils de partage de fichiers. C’est la couche qui influence directement l’exposition juridique, la confiance des clients et la continuité des activités.
Pourquoi c’est important. Même si des attaquants accèdent aux systèmes, une protection robuste à la couche des données peut rendre les fichiers volés illisibles et maintenir l’entreprise en marche. Le chiffrement au repos et en transit réduit les dommages liés à une exposition, tandis que des sauvegardes fiables et testées régulièrement permettent une restauration rapide après un incident de rançongiciel. La gouvernance des données précise aussi qui est propriétaire de quels renseignements et qui peut les utiliser ou les partager.
Risques courants dans les PME. On rencontre souvent des partages de fichiers grand ouverts où « Tout le monde » a accès à des dossiers sensibles parce que la structure a évolué de façon organique. Les sauvegardes sont parfois jointes au domaine et accessibles aux mêmes comptes que le rançongiciel compromettra, ce qui les rend faciles à chiffrer. Des fichiers sensibles dérivent vers des espaces infonuagiques personnels ou des fils de courriel, et très peu d’équipes disposent d’un schéma de classification convenu indiquant ce qui est public, interne, confidentiel ou réglementé.
À quoi ressemble une bonne pratique. Une couche des données efficace commence par une classification simple et comprise de tous, puis impose le chiffrement au repos pour les serveurs et les appareils, ainsi que TLS pour les données en mouvement. Des politiques de prévention des pertes de données (DLP) signalent ou bloquent les comportements à risque dans le courriel et le stockage en nuage, et l’architecture de sauvegarde suit la règle 3-2-1 — trois copies, deux types de média différents, une copie hors site ou immuable — jumelée à des tests de restauration planifiés.
L’accès est fondé sur les rôles et révisé périodiquement, en éliminant les permissions étendues de type « Tout le monde ». Les politiques de rétention et de gel juridique (legal hold) reflètent les exigences canadiennes en matière de protection de la vie privée et les besoins propres à votre secteur.
Mesures, responsables et échéancier. Au cours du premier mois, identifiez vos dix référentiels de données les plus sensibles et activez le chiffrement et les alertes DLP à leur emplacement, tout en vous assurant que les sauvegardes sont découplées de l’authentification du domaine. Effectuez un test de restauration réel pour prouver que la reprise fonctionne.
Durant les 30 à 60 jours suivants, réorganisez les permissions des partages de fichiers afin que l’accès corresponde aux rôles, supprimez les entrées génériques « Tout le monde », puis ajoutez un niveau de sauvegarde immuable ou hors ligne que le rançongiciel ne peut pas modifier.
Entre 60 et 90 jours, déployez des étiquettes de classification claires dans vos outils de collaboration, automatisez les politiques de rétention pour les types de documents courants et planifiez des exercices de restauration trimestriels afin d’en faire un réflexe opérationnel.
Indicateurs qui comptent. Suivez le pourcentage de sources de données critiques protégées par chiffrement et amenez-le vers une couverture complète. Comptabilisez le nombre de partages « Tout le monde » encore ouverts et visez le zéro. Documentez chaque exercice de restauration réussi et confirmez que votre objectif de point de reprise (RPO) et votre objectif de temps de reprise (RTO) répondent aux attentes de l’entreprise.

7) Couche des actifs — savoir ce que vous avez, le garder sécurisé
Définition. La couche des actifs correspond à l’inventaire de tout ce sur quoi vous vous appuyez : ordinateurs portables, serveurs, équipements réseau, ressources infonuagiques, licences logicielles, comptes privilégiés et services tiers critiques. C’est la fondation qui vous permet de corriger (patcher), durcir et intervenir en toute confiance.
Pourquoi c’est important. On ne peut pas défendre ce dont on ignore l’existence. Des inventaires exacts et mis à jour en continu vous permettent de repérer les anomalies, de prioriser l’application des correctifs et d’identifier les systèmes en fin de vie avant qu’ils ne deviennent des passifs. En situation d’incident, une vue claire des actifs aide les intervenants à trouver rapidement les systèmes touchés, à contenir l’exposition et à communiquer clairement avec les parties prenantes.
Risques courants dans les PME. Le TI fantôme s’infiltre dès que quelqu’un crée un abonnement infonuagique ou installe un logiciel sans en informer les TI, et ces actifs peuvent rester non gérés pendant des années. Les comptes de service et d’administration se multiplient sans propriétaire clairement défini, et de vieux systèmes d’exploitation persistent parce qu’ils pilotent un équipement de niche que personne ne veut remplacer. À travers tout cela, des feuilles de calcul tentent de suivre le rythme mais accusent naturellement un retard sur la réalité.
À quoi ressemble une bonne pratique. Une couche des actifs robuste s’appuie sur des outils de découverte automatisée pour recenser en continu le matériel, les logiciels et les ressources infonuagiques, puis rapprocher ces données des dossiers de la finance et des achats. Des bases de configuration alignées sur le CIS ou sur les pratiques exemplaires des fournisseurs sont définies et surveillées afin que les écarts soient détectés et corrigés.
Les appareils et services suivent un cycle de vie de la demande à la mise hors service, incluant l’effacement sécurisé et l’élimination documentée. Les fournisseurs clés sont classés par niveau de risque, et l’accès des tiers est protégé par l’authentification unique (SSO) et l’authentification multifacteur (AMF), exactement comme pour les employés.
Mesures, responsables et échéancier. Dans les 30 premiers jours, activez la découverte automatisée sur les réseaux sur site (on-premises) et les plateformes infonuagiques, puis rapprochez les résultats de votre inventaire financier pour résoudre les écarts et attribuer des propriétaires désignés aux actifs critiques.
Entre les jours 30 et 60, définissez des bases de configuration pour vos principales familles d’actifs, activez la détection des dérives de configuration et planifiez le retrait ou l’isolement des systèmes non pris en charge. D’ici 60 à 90 jours, formalisez la catégorisation des fournisseurs par niveau de risque, exigez le SSO et l’AMF pour l’accès des tiers et normalisez les processus d’élimination sécurisée afin que le matériel retiré ne devienne pas une source de fuite de données.
Indicateurs qui comptent. Mesurez le pourcentage d’actifs découverts par rapport à l’estimation et amenez-le au-delà de 98 %. Réduisez à zéro le nombre de systèmes en fin de vie, ou isolez-les avec des mesures compensatoires si le remplacement immédiat est impossible. Suivez la réalisation des revues annuelles de risque pour vos fournisseurs les plus critiques et vérifiez que leur accès respecte les mêmes normes d’authentification forte que celles en vigueur à l’interne.
Notre garantie en cybersécurité
“Chez Fusion Cyber Group, nous alignons nos intérêts sur les vôtres.“
Contrairement à de nombreux fournisseurs qui tirent profit de nettoyages de brèches longs et coûteux, notre objectif est simple : Arrêter les menaces avant qu’elles ne commencent et être à vos côtés si jamais l’une d’elles réussit à passer.
C’est pourquoi nous offrons une garantie en cybersécurité : dans le cas très improbable où une brèche traverserait nos défenses multicouches surveillées 24/7, nous prendrons tout en charge :
confinement des menaces,
intervention en cas d’incident,
correction,
élimination,
et reprise des activités—sans frais pour vous
Prêt à renforcer vos défenses en cybersécurité? Communiquez avec nous dès aujourd’hui pour obtenir votre évaluation GRATUITE de réseau et franchissez la première étape pour protéger votre entreprise contre les cybermenaces!