Dans le paysage de la cybersécurité en constante évolution, la couche des actifs est la source de vérité sur laquelle repose toute votre pile de sécurité. Si vous ne savez pas exactement quels appareils, services infonuagiques, applications SaaS, identités, magasins de données et dépendances tierces vous possédez, vous ne pouvez pas les protéger—ni le prouver. Considérez cette couche comme votre registre vivant : une source unique et faisant autorité qui indique ce qui existe, qui en est propriétaire, quelle est son importance et si c’est protégé.
Most incidents start with something unknown or unmanaged: a forgotten laptop, an unmonitored SaaS connector, a stale admin account, an outdated plug‑in. A strong assets layer exposes these blind spots and closes them before they turn into breaches.
Pourquoi la couche des actifs est-elle importante ?
Une couche des actifs saine réduit votre surface d’attaque et accélère le temps de réponse. Pour les équipes de PME canadiennes, les avantages sont pratiques et mesurables :
- Clarté opérationnelle. Inconnu ≈ non géré. La découverte continue et la notion de propriété transforment les suppositions en un carnet de tâches concrètes.
- Réponse aux incidents plus rapide. Lorsqu’une alarme se déclenche, les intervenants pivotent par actif, propriétaire et criticité—sans fouiller des feuilles de calcul.
- Préparation aux assurances et aux audits. Les assureurs et régulateurs s’attendent de plus en plus à des preuves de couverture (MFA, correctifs, EDR, sauvegardes). Un inventaire vivant relie les contrôles aux systèmes critiques et aide à éviter les refus de réclamation.
- Coûts réduits. Éliminez les outils en double, les licences inutilisées et les charges fantômes. Le budget s’aligne sur ce que vous exploitez réellement.
- Responsabilisation en matière de confidentialité. Le mappage des actifs à la sensibilité des données et aux propriétaires soutient les obligations de la LPRPDE (PIPEDA) et de la Loi 25 au Québec, la déclaration d’atteinte et les assurances aux clients.
- Continuité des activités. Lors d’une panne ou d’un incident, le registre montre les dépendances (ce qui casse si ce serveur ou cette application SaaS tombe), ce qui accélère le triage et la reprise.
À retenir pour les dirigeants : lorsque la couche des actifs est saine, les fenêtres de correctifs sont respectées, l’intégration/désaffectation est prévisible, les renouvellements se font plus vite, et la direction peut financer la sécurité en toute confiance parce que la couverture est visible et l’amélioration est mesurable.
Read More about the 7 Layers of Cybersecurity
Mises en œuvre clés de la couche des actifs (analyse approfondie)
Voici les dix blocs de construction que nous déployons de façon répétée pour les PME. Pour chacun, nous indiquons l’objectif, des étapes pratiques, les pièges à éviter et un KPI publiable.
1) Découverte et rapprochement continus
Objectif. Trouver en continu les appareils, utilisateurs, applications, ressources infonuagiques et intégrations—pas une fois par trimestre.
Mise en œuvre. Combinez les points de terminaison EDR/XDR, MDM/UEM, l’annuaire/IdP (Entra ID/Google/Okta), l’analyse réseau et les extractions cloud/SaaS. Planifiez une tâche nocturne qui déduplique par numéro de série/MAC/nom d’hôte/utilisateur et signale les inconnus.
Pièges. Traiter la découverte comme un projet ponctuel ; ignorer les sous-traitants et le personnel saisonnier ; ne pas analyser les segments invités/VLAN.
KPI. MTTD-U : temps moyen pour découvrir des appareils/utilisateurs/applications inconnus (cible < 24 h).
2) Registre unifié des actifs (CMDB/ITAM)
Objectif. Une liste fiable que les opérations, la sécurité et la finance approuvent.
Mise en œuvre. Suivez les champs requis : propriétaire ; unité d’affaires ; criticité (Élevée/Moyenne/Faible) ; environnement (prod/dev/test) ; cycle de vie (actif/fin de vie) ; couverture des contrôles (EDR, correctifs, sauvegardes, chiffrement, MFA) ; sensibilité des données (PII, financières, PI). Utilisez des étiquettes comme owner:, criticality:, env:, data:, eol: pour l’automatisation.
Pièges. Notes en texte libre ; doublons ; champs requis absents à l’intégration.
KPI. % d’actifs avec propriétaire + criticité + étiquettes de couverture (cible ≥ 95 %).
3) Inventaire des identités et des comptes
Objectif. S’assurer que chaque compte humain et de service est connu, à privilèges minimaux et attribué.
Mise en œuvre. Exportez les comptes et rôles de l’IdP, des consoles d’administration SaaS et des applications clés ; mappez-les à des personnes ou des systèmes ; appliquez des flux JML (arrivées-mobilités-départs) (désactivation le jour même au départ). Inventoriez les clés API, les applications OAuth et les comptes SSH/de service.
Pièges. Boîtes aux lettres orphelines ; mots de passe admin partagés ; jetons longue durée.
KPI. % d’identités avec MFA ; % de rôles privilégiés révisés mensuellement (cibles : ≥ 98 %, 100 %).
4) Dénombrement du cloud et du SaaS
Objectif. Capturer ce qui s’exécute dans vos locataires et qui peut y accéder.
Mise en œuvre. Extrayez les listes de ressources de M365/Google, d’IaaS/PaaS (Azure/AWS), du CRM/finance/RH et des intégrations majeures. Enregistrez les périmètres OAuth et les dates de dernière utilisation. Alertez sur les nouvelles connexions à privilèges élevés.
Pièges. Inscriptions SaaS fantômes ; connecteurs périmés avec larges périmètres ; absence de propriétaire.
KPI. % d’applications SaaS avec propriétaire nommé + périmètres révisés (cible ≥ 90 %).
5) Catalogue des fournisseurs et dépendances
Objectif. Savoir sur quels partenaires et tiers reposent vos opérations.
Mise en œuvre. Listez le MSP/MSSP, l’ISP/DNS, la sécurité du courriel, les paiements, les sauvegardes, la logistique et les API critiques. Consignez la résidence des données, les SLA, les contacts sécurité, les clauses d’avis d’incident et les étapes de désengagement.
Pièges. Payer des factures pour des fournisseurs que vous ne pouvez pas inventorier ; contacts d’urgence inconnus.
KPI. Exhaustivité du catalogue des fournisseurs ; % de fournisseurs avec addendum sécurité (cible ≥ 95 %).
6) Cartographie des données
Objectif. Relier les actifs à la sensibilité des données qu’ils stockent ou traitent.
Mise en œuvre. Identifiez bases de données, comptes de stockage, partages de fichiers, objets SaaS ; étiquetez PII/financières/PI ; consignez la rétention, le chiffrement et l’état des sauvegardes ; reliez aux propriétaires de systèmes.
Pièges. Considérer « le cloud » comme un lieu unique ; ignorer les exports et feuilles ad hoc.
KPI. % des magasins de données critiques avec sauvegardes testées trimestriellement (cible 100 %).
7) Contrôles de couverture
Objectif. Garantir que les protections requises sont installées et saines.
Mise en œuvre. Définissez une ligne de base par type d’actif : EDR/XDR, MDM/UEM, chiffrement du disque, correctifs, sauvegardes, filtrage courriel/DNS, DLP si applicable. Utilisez des stratégies de conformité pour bloquer l’accès des appareils sans agents.
Pièges. Compter les licences au lieu de vérifier des agents actifs et sains.
KPI. Couverture : EDR/correctifs/sauvegardes par actif géré (cible ≥ 95 %, viser ≥ 98 %).
8) Étiquetage et classification
Objectif. Faciliter l’automatisation et rendre les exceptions rares.
Mise en œuvre. Imposer un petit jeu d’étiquettes cohérent à l’intégration. Étiquettes requises : owner, criticality, env, data, eol. Exiger une étiquette exception: avec date d’expiration pour les écarts (p. ex., OS hérité) et un réviseur défini.
Pièges. Étiquettes « créatives » ; aucune échéance sur les exceptions ; étiquettes non appliquées au SaaS.
KPI. % d’actifs avec toutes les étiquettes obligatoires ; # d’exceptions expirées (cible 0).
9) Cycle de vie et changements
Objectif. Réduire le risque aux extrémités—approvisionnement et mise au rebut.
Mise en œuvre. Liez l’inventaire aux bons de commande ; bloquez les actifs en production tant que les agents + étiquettes ne sont pas présents. Pour la mise hors service, consignez l’assainissement des données (effacées/détruites) et le certificat de disposition d’actif.
Pièges. Appareils fantômes après désaffectation ; aucune preuve de destruction.
KPI. % d’actifs intégrés avec étiquettes complètes dès le jour 1 ; délai de retrait des FdV (< 30 jours).
10) Preuves et rapports
Objectif. Prouver la sécurité avec des chiffres simples et sincères.
Mise en œuvre. Publiez mensuellement : couverture par unité d’affaires ; inconnus découverts ; respect des SLA de correctifs ; révision des rôles privilégiés ; résultats des tests de sauvegarde ; carnet d’exceptions avec échéances.
Pièges. Indicateurs de vanité ; dissimulation des écarts ; absence de responsable par indicateur.
KPI. Une page exécutive livrée chaque mois avec une demande de décision.
Réalité publique (Cloud, SaaS et tiers)
Les systèmes et intégrations exposés au public sont pratiques—et risqués. Problèmes courants : inscriptions SaaS fantômes, jetons périmés, périmètres OAuth trop permissifs et postes de sous-traitants non gérés.
Identité et santé des appareils d’abord
Imposez SSO + MFA partout, avec des méthodes résistantes au hameçonnage pour les rôles finance et admin. Exigez des appareils sains et chiffrés pour l’accès administratif (bloquez les OS débridés/non pris en charge). Reliez la conformité de l’appareil à l’accès via des stratégies conditionnelles.
Contrôlez ce qui vous atteint
Placez des protections gérées (sécurité WAF/API, filtrage courriel, filtrage DNS) devant les services exposés. Enregistrez les systèmes protégés par chaque contrôle, testez trimestriellement et suivez la couverture comme KPI (p. ex., 100 % des points d’extrémité publics derrière WAF/sécurité API).
Courtage de l’accès des tiers
Accordez des identifiants à durée de vie courte et à périmètre restreint ; centralisez l’approbation ; révisez l’accès mensuellement. Résiliez automatiquement à la fin de projet ou au changement de fournisseur. Conservez une fiche de contacts fournisseurs avec numéros d’incident 24/7.
Hygiène pratique
Faites tourner les jetons trimestriellement (ou lors de changements de personnel), retirez les applications inutilisées et interdisez le stockage non géré pour les fichiers sensibles. Incluez des annexes de sécurité fournisseur à l’approvisionnement—pas après un incident.
À quoi ressemble le « bon » (portrait de maturité)
Fondation.
- Découverte nocturne ; inconnus triés chaque semaine.
- Un registre des actifs avec propriétaires, criticité, étiquettes de données, cycle de vie.
- SSO + MFA imposés pour tous ; agents EDR/correctifs sur tous les postes gérés.
- Magasins de données listés avec état des sauvegardes ; liste des fournisseurs avec SLA.
- Trousse de preuves (exports de couverture, politique MFA, résultats de correctifs) créée trimestriellement.
Avancé.
- Inventaire Cloud/SaaS automatisé ; périmètres OAuth révisés mensuellement.
- JML relié aux RH pour changements d’accès le jour même ; accès privilégié revu mensuellement.
- Couverture > 95 % pour EDR/correctifs/sauvegardes ; appareils inconnus bloqués par défaut.
- Remplacements FdV planifiés et suivis ; carnet d’exceptions avec échéances.
- Exercice de table complété ; leçons intégrées aux étiquettes/guide opératoire.
Optimal.
- CAASM/ASM consolide les flux ; comptes de service tournés automatiquement.
- Posture SaaS gérée en continu ; alertes de dérive vers SIEM/XDR et SOC.
- Trousse de preuves générée à la demande ; tableaux de bord par unité au comité de direction.
- Cycle d’amélioration continue (trimestriel) : revue des tendances, rattachements budgétaires, registre d’acceptation des risques.
Auto-évaluation (cinq questions). Découvrons-nous de nouveaux appareils/utilisateurs en moins de 24 heures ? Pouvons-nous montrer la couverture agents/correctifs/sauvegardes par unité ? Tous les rôles admin sont-ils à privilèges minimaux et révisés mensuellement ? Savons-nous où résident les données réglementées et qui en est propriétaire ? Pouvons-nous retirer tout actif avec preuve d’assainissement en quelques jours ?
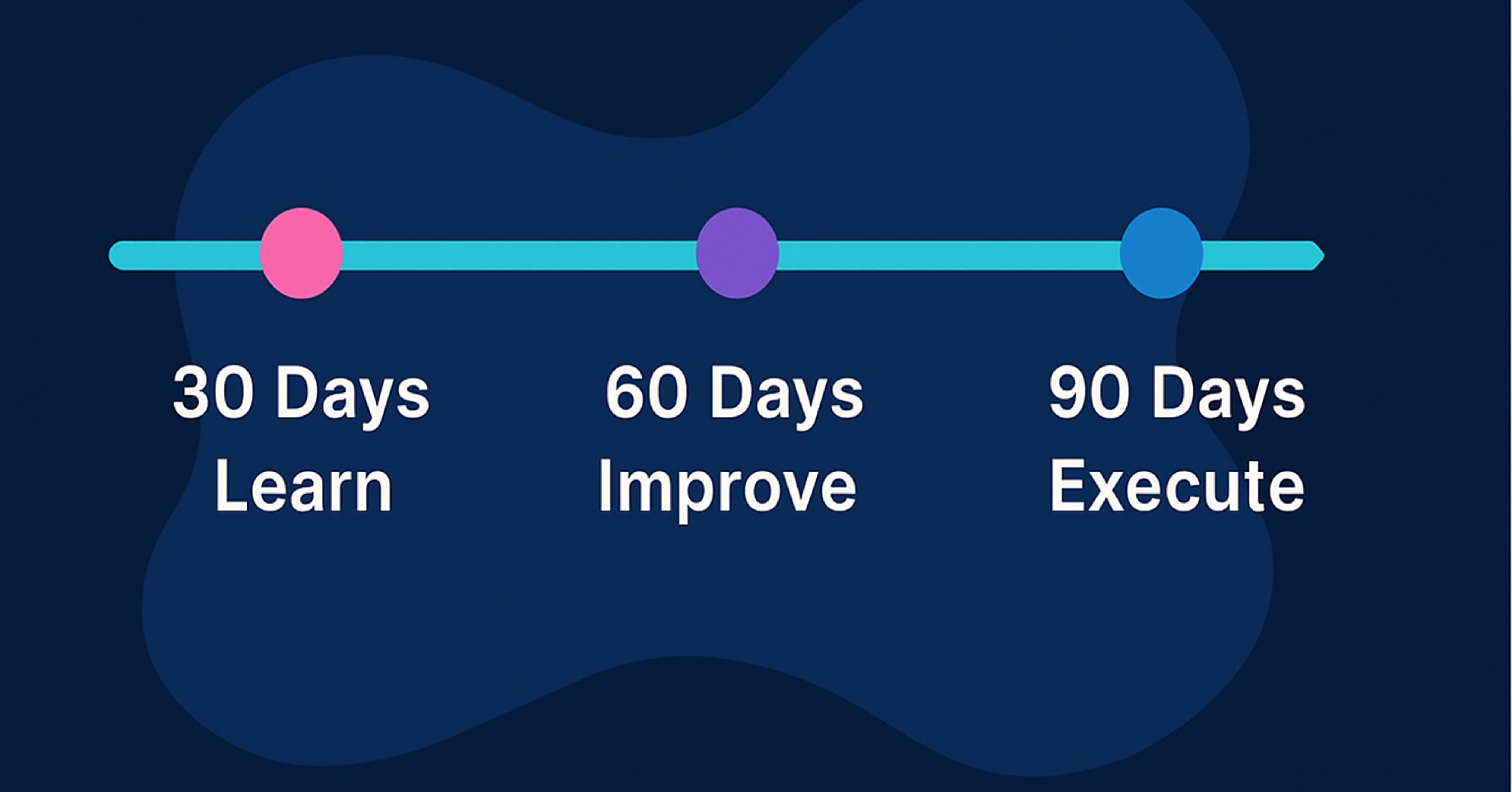
Plan 30–60–90 jours (adapté aux PME)
Jours 1–30 — Stabiliser et voir (Responsable : chef TI ; Commanditaire : chef de l’exploitation/chef des finances)
- Agréger la découverte depuis EDR/MDM/IdP/cloud dans un seul registre ; dédupliquer ; étiqueter propriétaire/criticité/données.
- Bloquer les inconnus du réseau/VPN/SSO jusqu’à enregistrement ; publier le carnet.
- Imposer la MFA pour tous les utilisateurs ; méthodes résistantes au hameçonnage pour admin/finance.
- Gains rapides : supprimer les comptes admin périmés ; étiqueter/planifier les remplacements FdV ; sauvegarder les magasins de données critiques ; consigner le top 10 des applications SaaS et propriétaires.
- Artéfacts : registre des actifs v1 ; politique MFA ; matrice de sévérité des correctifs ; liste de contacts fournisseurs.
- Critères de sortie : ≥ 90 % d’actifs étiquetés ; ≥ 95 % de MFA sur les identités ; inconnus âgés > 7 jours = 0.
Jours 31–60 — Durcir et automatiser (Responsable : sécurité/SOC ; Soutien : opérations TI)
- Relier JML pour que embauches, mobilités et départs mettent à jour accès et état des appareils le jour même.
- Définir des SLA de correctifs par sévérité et criticité des actifs ; ouverture automatique de billets en cas d’échec.
- Automatiser les exports SaaS/OAuth ; alerter sur les nouvelles connexions à privilèges élevés ; réviser les périmètres.
- Ajouter l’inventaire des fournisseurs au registre, y compris SLA, contacts, résidence des données et procédures de désengagement.
- Artéfacts : guide JML ; liste de vérification revue OAuth ; tableau de bord des correctifs ; liste de vérif. désengagement fournisseur.
- Critères de sortie : couverture ≥ 95 % (EDR/correctifs/sauvegardes) ; latence JML ≤ 1 jour ouvrable.
Jours 61–90 — Moderniser et mesurer (Responsable : vCISO/directeur TI)
Critères de sortie : ≥ 98 % de couverture EDR/correctifs/sauvegardes ; 100 % des rôles privilégiés revus mensuellement ; trousse de preuves générée en < 1 heure.
Introduire CAASM/ASM ou consolider les flux dans le SIEM/XDR pour corrélation et chasse.
Publier une page mensuelle : tendances de couverture, MTTD-U, carnet d’exceptions, décisions requises.
Exécuter un exercice de table (portable perdu, jeton API compromis, sous-traitant malveillant) ; mettre à jour étiquettes/guide.
Artéfacts : gabarit de note exécutive ; trousse de preuves ; livrables de l’exercice ; registre des risques mis à jour.
Responsables et artéfacts (style RACI)
- Commanditaire exécutif (COO/CFO). Définit la politique, approuve les exceptions de risque avec échéance, finance les remplacements. Accountable.
- Chef TI / vCIO. Détient le registre des actifs, les étiquettes, les intégrations et le cycle de vie. Responsible.
- Chef sécurité / vCISO. Définit les normes de couverture (MFA, correctifs, EDR, sauvegardes), révise les exceptions et produit la trousse de preuves. Accountable.
- Propriétaires d’actifs (chefs de service). Valident l’exactitude mensuellement ; confirment la classification des données et la criticité d’affaires. Responsible.
- Finances/Approvisionnement. Aligne achats, contrats et budgets FdV ; s’assure que les fournisseurs sont inventoriés avant paiement. Consulted.
- SOC (Fusion Cyber). Surveille la dérive, corrèle les anomalies et répond 24×7×365. Responsible/Consulted.
Artéfacts essentiels à maintenir : registre vivant des actifs ; guides JML ; catalogue des fournisseurs avec SLA et résidence des données ; cartographie des données ; registre des exceptions avec échéance ; note mensuelle ; trousse de preuves (exports de couverture, posture MFA, résultats SLA de correctifs, rapports de tests de sauvegarde).
Extrait de politique (à utiliser/adapter). « Tous les actifs (appareils, ressources infonuagiques, applications SaaS, identités, magasins de données) doivent être enregistrés avec les étiquettes propriétaire, criticité, environnement, cycle de vie et couverture avant l’usage en production. Les exceptions exigent l’étiquette exception: avec échéance ≤ 90 jours et l’approbation du commanditaire exécutif. »
Indicateurs qui démontrent une vraie réduction du risque (avec cibles)
- Couverture : % d’actifs avec agents EDR/MDM/sauvegarde ; % d’identités avec MFA ; % de points d’extrémité publics derrière une sécurité WAF/API. Cibles : 98 % / 98 % / 100 %.
- Hygiène : Respect des SLA de correctifs par sévérité (Critique 7 jours, Élevée 14 jours, Moyenne 30 jours) ; jours pour retirer les FdV (< 30 jours) ; temps de rotation des identifiants/clés (< 1 jour pour événements à haut risque).
- Découverte : MTTD-U—temps moyen pour découvrir des appareils/utilisateurs/applications inconnus (< 24 h) ; inconnus âgés > 7 jours (0).
- Propriété : % d’actifs avec propriétaire nommé + étiquette de sensibilité (≥ 95 %) ; comptes orphelins fermés par mois (tendance croissante vers 0 en régime stable).
- Risque : Arriéré de vulnérabilités sur actifs critiques (tendance à la baisse) ; exceptions expirées (0) ; taux de réussite de restauration des magasins critiques (100 %).
Comment rapporter. Une page, chaque mois : trois tendances (couverture, MTTD-U, SLA de correctifs), une exception nécessitant une décision, un succès pertinent pour le client (p. ex., abus API bloqué). Conservez des chiffres cohérents et annotés.vel confidence, insurer trust, and customer reassurance.
Principaux risques de la couche des actifs (anti-modèles et correctifs)
- Licence ≠ couverture. Compter les sièges comme si les agents étaient sains. Correctif : mesurer la santé active des agents par actif ; alerter sur les écarts.
- Dérive de la feuille de calcul. Inventaire mis à jour manuellement puis oublié. Correctif : automatiser la découverte + rapprochement nocturne ; verrouiller la feuille, migrer vers un système.
- Angles morts SaaS et identité. Inscriptions fantômes et jetons périmés. Correctif : centraliser le SSO ; exporter les périmètres OAuth ; revues mensuelles ; révoquer les applications dormantes.
- Absence de contexte d’affaires. Appareils sans propriétaires ni criticité. Correctif : exiger les étiquettes à l’intégration ; bloquer l’accès aux actifs sans propriétaire.
- Focalisation uniquement sur les postes. Ignorer le cloud, les magasins de données et les fournisseurs. Correctif : élargir la portée et en faire une routine, pas un projet.
- Paramétrer-et-oublier. Aucune cadence de revue ni de preuves. Correctif : revue opérationnelle hebdomadaire ; note mensuelle pour la direction ; exercice trimestriel.
Comment Fusion Cyber aide (sobrement, sans vente agressive)
Évaluer. Découverte externe et extraction interne d’inventaire (EDR/MDM/IdP/cloud/SaaS). Vous recevez une liste priorisée—ce qu’il faut corriger maintenant, planifier et surveiller.
Déployer. Mise en place ou réglage de la découverte, du CAASM/ASM, des bases de couverture (MFA, EDR, correctifs, sauvegardes) et des flux JML. Les configurations et exceptions sont étiquetées, gérées en version et assorties d’une échéance.
Surveiller. Notre SOC 24×7×365 corrèle l’activité identité, poste, réseau et SaaS pour détecter la dérive et intervenir avant l’escalade.
Répondre et récupérer. Lors d’incidents, nous isolons les actifs, faisons tourner les identifiants, révoquons les jetons et coordonnons la reprise. Les clients entièrement intégrés bénéficient de notre garantie financière en cybersécurité—intervention, confinement et reprise à nos frais.
Cogéré, canadien et bilingue. Nous respectons la résidence des données et fournissons des communications et rapports en français et en anglais.
Prêt à renforcer votre couche des actifs ? Commencez ici : https://fusioncyber.ca/get-started/ ou écrivez à info@fusioncyber.ca.

Mot de la fin
La couche des actifs est votre carte et votre grand livre. Avec une découverte continue, une propriété claire, une couverture que vous pouvez prouver et des indicateurs simples, vous remplacez les suppositions par la gouvernance. Pour les dirigeants de PME, la voie est pratique : stabiliser l’existant, automatiser les quelques processus qui changent réellement les résultats et mesurer les progrès d’une manière que votre conseil, votre assureur et vos clients comprennent.
Si vous ne priorisez que trois actions ce trimestre, choisissez celles-ci : (1) centraliser la découverte dans un registre vivant avec propriétaires et étiquettes, (2) imposer SSO + MFA partout avec JML le jour même et (3) porter la couverture à > 95 % pour EDR/correctifs/sauvegardes avec des SLA de correctifs. Ces étapes réduisent rapidement le risque et préparent la réussite de toutes les autres couches.
👉 Protégez votre PME maintenant – Parlez à un expert en cybersécurité
Liens a la Une:
Aperçu des solutions de Fusion Cyber
NIST CSF 2.0 – Gestion des actifs
Guide canadien de gestion des actifs TI
FAQ:
Comment l’approche Zero Trust influence-t-elle la sécurité de la couche applicative ?
Zero Trust part du principe que rien—interne ou externe—n’est fiable par défaut. À la couche applicative, chaque requête est vérifiée (identité de l’utilisateur, posture de l’appareil, validité du jeton) avant l’accès. Des contrôles comme le moindre privilège, l’autorisation basée sur les rôles et attributs, et les jetons de courte durée appliquent Zero Trust. Cela réduit les mouvements latéraux, limite l’impact d’une fuite d’identifiants et empêche les applis publiques de surexposer leur logique. Les PME gardent ainsi un meilleur contrôle des données, réduisent l’exposition et simplifient la conformité.
Quels indicateurs réalistes une PME devrait-elle suivre pour mesurer la maturité de la sécurité applicative ?
Parmi les indicateurs clés :
Ratio des défauts détectés avant vs après production (cible : > 70 % avant prod)
MTTR des vulnérabilités critiques — des jours, pas des semaines
Couverture WAF/API (% d’endpoints publics protégés)
Nombre d’attaques par « credential stuffing »/bots bloquées (normalisé par le volume de connexions)
Délai pour faire tourner/révoquer les secrets (fréquence et rapidité)
Adoption du « refus par défaut » en trafic est–ouest (mTLS/service mesh)
Le suivi longitudinal montre la réduction du risque, éclaire conseils/assureurs et guide l’investissement.
SITUATION
Les PME s’appuient sur des appareils, du cloud, du SaaS, des identités, des dépôts de données et des fournisseurs; la couche des actifs est le registre vivant qui indique ce qui existe, qui en est propriétaire, sa criticité et son niveau de protection.
COMPLICATION
Les actifs inconnus/non gérés — SaaS fantômes, comptes admin périmés, portables oubliés, données non étiquetées — provoquent des incidents; les feuilles dérivent, les licences ≠ la couverture et les audits/assureurs exigent des preuves difficiles à fournir.
QUESTION
Comment bâtir rapidement une couche des actifs fiable sans alourdir l’outillage ni augmenter les effectifs?
RÉPONSE
Agrégiez la découverte continue dans un registre balisé, automatisez JML, imposez SSO+AMF, atteignez ≥95 % de couverture EDR/correctifs/sauvegardes et publiez des ICP mensuels.
Notre Garantie Cybersécurité
“Chez Fusion Cyber Group, nous alignons nos intérêts avec les vôtres.“
Contrairement à de nombreux fournisseurs qui profitent de longues interventions coûteuses après une brèche, notre objectif est simple: stopper les menaces avant qu’elles ne réussissent et vous accompagner si jamais l’une d’elles passait entre les mailles du filet.
C’est pourquoi nous offrons une garantie cybersécurité: dans le cas très improbable où une brèche surviendrait malgré nos défenses multi-couches surveillées 24/7, nous prendrions en charge, sans frais supplémentaires :
contenir la menace,
gérer l’incident,
appliquer les mesures correctives,
supprimer la menace,
et rétablir vos activitées—sans frais suplémentaires.
Ready to strengthen your cybersecurity defenses? Contact us today for your FREE network assessment and take the first step towards safeguarding your business from cyber threats!